Why vibe coders get stuck

In this post I’ll discuss how AI agents work, how LLMs impact the quality of vibe-coded applications and what we can do to mitigate it.
There are three ways in which we can control the quality of a vibe coded application:
Keep it small.
Lean towards learning more technical concepts.
Wait for AI and overall systems to improve.
AI agents and LLM limitations
To understand how AI agents work, we must understand how modern Large Language Models work. In short, LLMs are deep neural networks built on the transformer architecture. They are trained on the entire internet’s content to predict the next token (or word), given a set of input tokens (or prompt).
AI agents are new software systems that rely on the reasoning capabilities of LLMs to perform tasks that conventional, deterministic software systems wouldn’t be able to do.
But LLMs come with limitations. So one of the roles of agentic systems is to supplement them. (Bonus: another role is to execute the decisions of the LLM.)
There are two attributes that impact the quality of vibe coded applications:
Context window limitations.
Stochasticity.
The context window
LLMs don’t have memory. All they store are the trained weights of the neural network. Instead, they rely on an input sequence of tokens (a prompt) to generate more tokens.
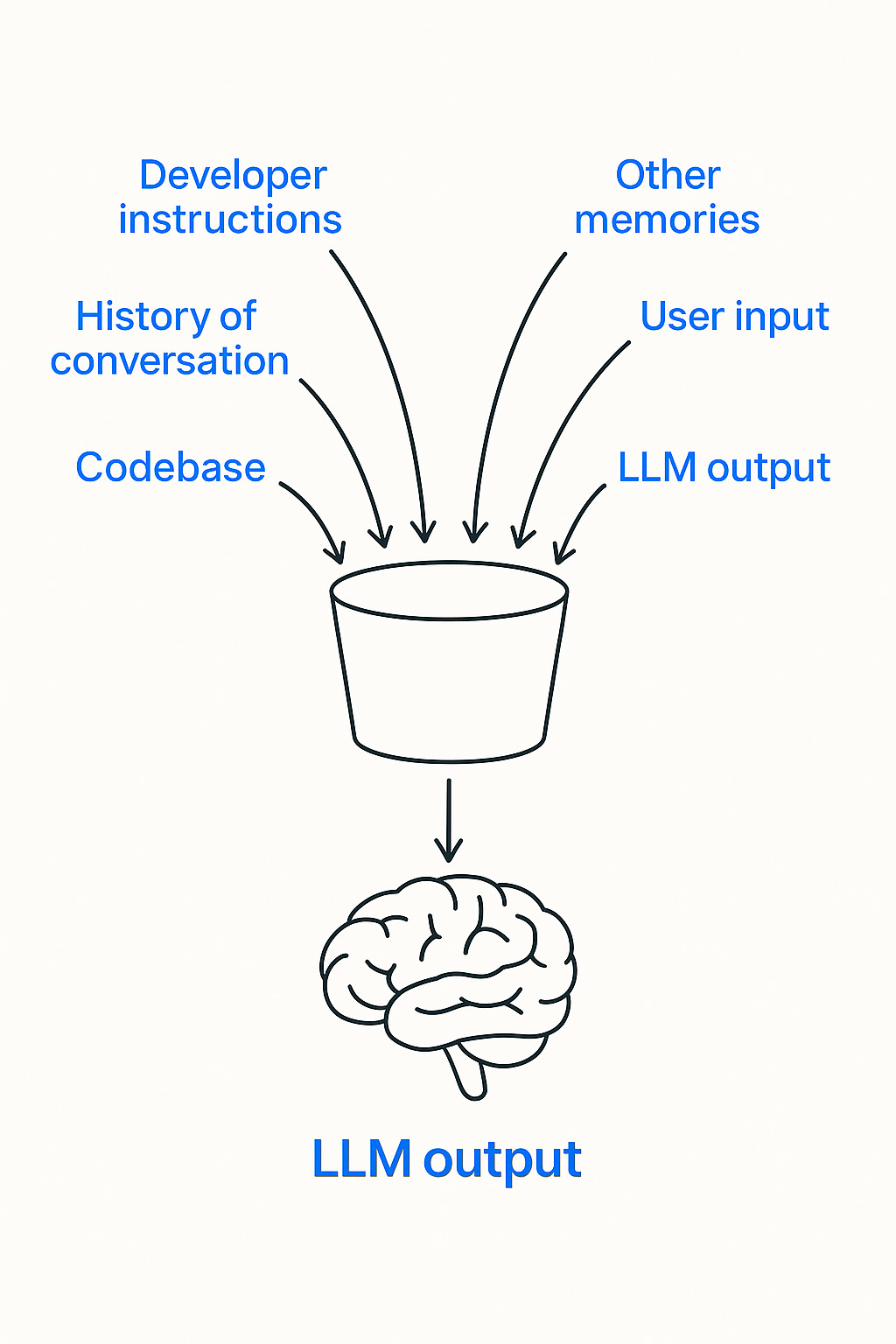
The context window is the maximum number of tokens that an LLM can process at once. We can think of it as a bucket; it can only hold so much.
As of June 2025, the context window size of GPT o3 is 200,000 tokens (or 150,000 words or Bram Stoker’s Dracula).
But the overall size is not the only issue. LLMs also “forget” information within their context window. The optimal size lies within less than 50% of the actual size.
For AI coding agents, some of the information that goes into the bucket is: the user input, the codebase, the history of the conversation, the output of the LLM as it cycles over multiple steps, developer instructions and other memories. That’s a lot.
AI engineers have to design clever ways to put the right amount of data into the bucket.
What it means for our vibe coded application is that our agent might “forget” certain parts of the code or why it made a decision or even what the original instructions were.
Stochasticity
LLMs are non-deterministic. They’re trained to predict, probabilistically, the next token given some context. Even for the same input, there is no guarantee that models will return the same output 100% of the time.
We all have seen how trying to build the same application will yield multiple variations of the same. It’s likely that each of those applications will use different architectural patterns. What is more concerning are hallucinations.
For a vibe coded application, what it means is that there is a probability (while low) that the code that our agent generates is wrong.
How to improve the quality of vibed code
Keep it simple
It’s easy to see how as our application grows in complexity, these two issues compound - the agent has more things to remember and more chances to make a bad decision.
Additionally, for true vibe coders, more complexity means more unknowns.
In essence, that’s why vibe coders get stuck. We’re dealing with a black box of code whose internals we might not understand and that were probabilistically generated. At some point, the agent might take a wrong turn from which it’s hard to return. And then more issues cascade.
We can keep it simple or we can guide the agent out.
Learn more technical concepts
And I don’t mean learning how to code.
The most successful vibe coders I know use a variety of tools. They not only use Lovable, Bolt or Replit; they use Cursor or Windsurf; they write PRDs; and use n8n, make.com or Zapier. They mitigate the chances of a single point of failure.
Something else useful is to learn how things come together - systems thinking. For example: what is the role of the frontend, what is the role of the backend, how to validate results in the database, how to look at the logs, how to use github, how to test APIs, etc. (Tip: Through this newsletter I hope that I can share some of that knowledge).
If we want to build more complex applications, we need to be more intentional about verifying the decisions of the agent. We can improve our skills of getting unstuck.
Wait for AI and systems to improve
But if we don’t want to meet AI in the middle, we might just have to wait a few months.
ChatGPT came out in November 2022; GPT4, in March 2023; Claude 3.5, in June 2024; and Claude 4, in May 2025. Each of these models had a noticeable improvement in the quality of their code.
Additionally, there is much ongoing research and engineering to improve the capabilities, robustness and reliability of agentic systems across the board, including AI coding agents.
So, the future is bright.
And right now is a perfect time to learn how to supercharge our vibe coding and learn how software is developed at a high level. The reason is simple: it gives us an edge.